This blog details the steps in performing a demographic analysis using the coding language R in R Studio and visualizing in Tableau. Examples will come from the demographic analysis I conducted for the 2023 AI Housing Project for Data Science for the Public Good.
In short, a demographic analysis is a study of demographic characteristics. According to Oxford Languages (2023), demographic characteristics are “statistical data relating to the population and particular groups within it.”
So, why conduct a demographic analysis? Demographic analyses are useful for various things, from finding suitable locations for a new factory to discovering patterns and trends in demographic data. The 2023 AI Housing Project demographic analysis was used to discover places in Iowa that could best benefit from an AI application to evaluate the conditions of the housing stock.
There are foursteps to a demographic analysis:
Determine analysis criteria.
Gather data.
Transform data.
Visualize data.
Determining Analysis Criteria
This step is entirely personal. Depending on the nature of your analysis, you will want to analyze different types of demographic data. Your options are, but not limited to, data on age, race, ethnicity, gender, marital status, income, education,and employment. More detailed data is available about each.
For the 2023 AI Housing Project, I planned to analyze the following demographic data:
Age
Population size
Housing
Occupancy rates
Income
Jobs and employment
I chose the following demographic characteristics because they can tell something about the condition of a community. For the 2023 AI Housing Project, I was looking for struggling communities. Typically, struggling communities have a declining population. They can have a higher median age if new individuals are not moving into town and having kids and existing, young residents are moving out. A low median house value and high median house age can also indicate a struggling community. A high median house age can reveal that new housing is not being built in the community. A low median income is not a great sign or a low percent change in income. Employment statistics are important because there will only be money to invest in a community if people are employed. I was interested in the percentage of the workforce that commuted to work because that gives us information on where jobs are located. If people are commuting, there needs to be more jobs in town. A low number of jobs does not encourage population growth.
For a more comprehensive analysis, I could also analyze the spatial relationship of healthcare options, daycare options, grocery stores, utilities, restaurants, shops, and schools to places in Iowa. Small, thriving, rural towns have access to at least one or more stated features.
Gathering Data
Once you have decided on the demographic data you will analyze, it is time to start the data collection process. Many demographic data can be found via the United States Decennial Census or the American Community Survey (ACS). The U.S. census is one of the best places to gather demographic data because it counts every resident in the United States. It has a very low inaccuracy, but the U.S. census is only conducted every ten years. For more recent data, the American Community Survey (ACS) is your best bet. The ACS has more detailed demographic data, and is conducted every five years for the entirety of the United States and every year for places with a population over 65,000. The ACS does not count every individual resident in the United States and instead relies on surveying a proportion of the population to create estimates of the demographics. Thus, it can be inaccurate and provides a margin of error. It is best used for data on the changing population, housing, and workforce.
You use the get_decennial() and get_acs() functions included in the Tidycensus package to pull from these data sources in R. Both functions operate off the same set of criteria. You must only specify a geography, variable, and year to pull data.
# install.packages("tidyverse")# install.packages("tidycensus")library(tidyverse)library(tidycensus)# getting total populationtotal_population <-get_decennial(geography ="state",variable ="P001001",year =2010)head(total_population)
# A tibble: 6 x 4
GEOID NAME variable value
<chr> <chr> <chr> <dbl>
1 01 Alabama P001001 4779736
2 02 Alaska P001001 710231
3 04 Arizona P001001 6392017
4 05 Arkansas P001001 2915918
5 06 California P001001 37253956
6 22 Louisiana P001001 4533372
# getting median incomemedian_income <-get_acs(geography ="state",variable ="B19013_001",year =2010)head(median_income)
The get_acs() example above is pulling median income data from the 2010 5-Year American Community Survey at the state level. By default, get_acs() will pull data from the 5-Year ACS instead of the 1-Year ACS unless specified with the survey = argument.
# pulling from 1-Year ACSmedian_income_1year <-get_acs(geography ="state",variable ="B19013_001",year =2010,survey ="acs1")
Getting data from the 2010 1-year ACS
The 1-year ACS provides data for geographies with populations of 65,000 and greater.
# pulling from 5-Year ACSmedian_income_1year <-get_acs(geography ="state",variable ="B19013_001",year =2010,survey ="acs5")
Getting data from the 2006-2010 5-year ACS
A full list of geographies for the Decennial Census and ACS can be found here. The full list of available Census API variable codes can be found here, and the 5-Year ACS API variable codes can be found here. The API variable codes I used for the demographic analysis are located on a different page on my blog. Further modifications can be made to the get_decennial() and get_acs() functions. To learn more, check out Kyle Walker’s textbook on Tidycensus.
The Census and ACS are great data sources, but other sources are often available for specific demographic data. If not pulling data using Tidycensus, you can read data from spreadsheets into R Studio. For example, I used the LEHD Origin-Destination Employment Statistics (LODES)2020 Workforce Area Characteristics(WAC) and the 2020 Residential Area Characteristics(RAC) data to create more detailed analyses for jobs and the workforce. The WAC and RAC data structure information can be found here.
The WAC and RAC data are downloaded as CSV files from their respective locations. To view them in R Studio, you use the function read.csv(). The function read.csv() takes the argument file as a file path to read tabular data.
ia_wac.csv <-read.csv("C:/Users/Kailyn Hogan/OneDrive - Iowa State University/Documents/GitHub/Housing/demographics/demographic analysis/Datasets/ia_wac_S000_JT00_2020.csv")head(ia_wac.csv)
Once the file is read, it acts like any other data frame in R Studio. The data can be transformed and mutated to your liking.
Transforming the Collected Data
Standardizing Data
When conducting a demographic analysis, or any analysis for that matter, making sure to transform the data in a way that leads to easy visualization is important. Even more important is to ensure the transformation is clear from misleading the viewer.
I worked with places of different sizes for the 2023 AI Housing Project’s demographic analysis. Initial observations can be inaccurate because the data is not standardized. For example, you cannot accurately compare the number of male individuals under five for Des Moines, Iowa, to Alburnett, Iowa. Des Moines appears to have a much larger proportion of male individuals under five than Alburnett because it is a much larger city in comparison.
# pulling 5-Year ACS estimate for Des Moinesdsm <-get_acs(geography ="place",state ="IA",variable ="B01001_003",year =2021) %>%filter(NAME =="Des Moines city, Iowa")# pulling 5-Year ACS estimate for Alburnettalburnett <-get_acs(geography ="place",state ="IA",variable ="B01001_003",year =2021) %>%filter(NAME =="Alburnett city, Iowa")print(dsm["estimate"])
# A tibble: 1 x 1
estimate
<dbl>
1 7468
print(alburnett["estimate"])
# A tibble: 1 x 1
estimate
<dbl>
1 11
An accurate comparison can be derived when the data is standardized and turned into percentages of the total male population. We can see that Des Moines only has a slightly larger percentage of their male population under five than Alburnett.
# pulling male estimate under 5 and total male population for Des Moinesdsm <-get_acs(geography ="place",state ="IA",variable =c("total"="B01001_002","under5"="B01001_003"),year =2021,output ="wide") %>%filter(NAME =="Des Moines city, Iowa") %>%mutate(percent = under5E / totalE *100)# pulling male estimate under 5 and total male population for Alburnettalburnett <-get_acs(geography ="place",state ="IA",variable =c("total"="B01001_002","under5"="B01001_003"),year =2021,output ="wide") %>%filter(NAME =="Alburnett city, Iowa") %>%mutate(percent = under5E / totalE *100)print(dsm["percent"])
# A tibble: 1 x 1
percent
<dbl>
1 7.13
print(alburnett["percent"])
# A tibble: 1 x 1
percent
<dbl>
1 3.03
Thus, standardization of data is important for an accurate analysis later on. The easiest way to standardize data is to change it into percentages.
Transformation
Let’s run through an example of transforming the data. For this example, we will be pulling the variables for Total Population by Age and Sex to create a new data frame that contains only the percentage of the population under eighteen and over sixty-five separated by sex. The Decennial Census and the ACS break up age groups seemingly haphazardly, so there is no easy variable to pull the total population under eighteen and over sixty-five. To get these statistics, we must pull the age groups that fall into these categories and then sum them to get the total. To start, let’s pull the variables from the 5-Year ACS.
# pull ACS estimates for malemale <-get_acs(geography ="place",state ="IA",variable =c("under5"="B01001_003","a5to9"="B01001_004","a10to14"="B01001_005","a15to17"="B01001_006","a65to66"="B01001_020","a67to69"="B01001_021","a70to74"="B01001_022","a75to79"="B01001_023","a80to84"="B01001_024","over85"="B01001_025","total"="B01001_002"),year =2021,output ="wide") %>%mutate(NAME =str_remove(NAME, " city, Iowa"))# now pull estimates for femalefemale <-get_acs(geography ="place",state ="IA",variable =c("under5"="B01001_027","a5to9"="B01001_028","a10to14"="B01001_029","a15to17"="B01001_030","a65to66"="B01001_044","a67to69"="B01001_045","a70to74"="B01001_046","a75to79"="B01001_047","a80to84"="B01001_048","over85"="B01001_049","total"="B01001_026"),year =2021,output ="wide")%>%mutate(NAME =str_remove(NAME, " city, Iowa"))
I have gone through and named the variables so that finding the total will be more intuitive. Now let’s add the age groups together to get the total population. When summing the variables, we want to remember that ACS data are estimates. They are not full counts of the population and, thus, have margins of error. We must also calculate a margin of error for the total population.
# create new columns for under18 and over 65 for both male and female# create new columns for the new margins of errormale <- male %>%mutate(under18E =round(under5E + a5to9E + a10to14E + a15to17E)) %>%mutate(under18M =round(sqrt(under5M^2+ a5to9M^2+ a10to14M^2+ a15to17M^2))) %>%mutate(over65E =round(a65to66E + a67to69E + a70to74E + a75to79E + a80to84E + over85E)) %>%mutate(over65M =round(sqrt(a65to66M^2+ a67to69M^2+ a70to74M^2+ a75to79M^2+ a80to84M^2+ over85M^2)))female <- female %>%mutate(under18E =round(under5E + a5to9E + a10to14E + a15to17E)) %>%mutate(under18M =round(sqrt(under5M^2+ a5to9M^2+ a10to14M^2+ a15to17M^2))) %>%mutate(over65E =round(a65to66E + a67to69E + a70to74E + a75to79E + a80to84E + over85E)) %>%mutate(over65M =round(sqrt(a65to66M^2+ a67to69M^2+ a70to74M^2+ a75to79M^2+ a80to84M^2+ over85M^2)))
Let’s also add a column for gender so we know what values are which.
# add a new column for gendermale <- male %>%mutate(gender ="Male")female <- female %>%mutate(gender="Female")
Now that we have the gender defined and the total populations under eighteen and over sixty-five, we can combine the data frames and calculate the percentages. To calculate the percentages of the population under eighteen and over sixty-five, we will use the summarize() function. We will combine it with the group_by() function to make sure the percentages are calculated by sex.
# combine the data framesage <- female %>%bind_rows(male)# group by gender# create new columns for percent under 18 and percent over 65 using summarize()sum_age <- age %>%group_by(NAME,gender) %>%summarize(prc_under18E =sum(under18E)/sum(totalE),prc_under18M =sqrt(sum(under18M^2) /sum(totalE)^2+ (sum(under18E)^2*sum(totalM^2)) /sum(totalE)^4),prc_over65E =sum(over65E)/sum(totalE),prc_over65M =sqrt(sum(over65M^2) /sum(totalE)^2+ (sum(over65E)^2*sum(totalM^2)) /sum(totalE)^4))
`summarise()` has grouped output by 'NAME'. You can override using the
`.groups` argument.
sum_age
# A tibble: 2,056 x 6
# Groups: NAME [1,028]
NAME gender prc_under18E prc_under18M prc_over65E prc_over65M
<chr> <chr> <dbl> <dbl> <dbl> <dbl>
1 Ackley Female 0.238 0.0604 0.247 0.0627
2 Ackley Male 0.233 0.0648 0.154 0.0400
3 Ackworth Female 0.422 0.323 0.144 0.223
4 Ackworth Male 0.207 0.254 0.190 0.352
5 Adair Female 0.252 0.130 0.204 0.0918
6 Adair Male 0.229 0.121 0.132 0.0686
7 Adel Female 0.242 0.0650 0.135 0.0440
8 Adel Male 0.337 0.0776 0.0911 0.0331
9 Afton Female 0.257 0.115 0.265 0.101
10 Afton Male 0.199 0.0931 0.149 0.0785
# i 2,046 more rows
The resulting data frame, sum_age, holds the percent population under eighteen and over sixty-five for all places in Iowa.
WHAT DID I TRANSFORM FOR MY ANALYSIS ??!?!?!?!?!?!?!!
Data Visualization
We will switch to Tableau for the data visualization portion of the demographic analysis. Tableau is a data analytics software used to create visualizations. R Studio can also create visualizations, but it is much more basic. R Studio excels in making standard visualizations, while Tableau can create stories that bring the data visualizations to life, and users can fully interact with them.
Tableau creates visualizations based on data found in spreadsheets. It will accept both Excel files and CSV files. We will turn our collected data into CSV files for further visualization in Tableau.
To convert our data frames of collected data into CSV files, we will use the function write.csv(). The function write.csv() takes the arguments x and file. X relates to the object to be written, and file represents the name of the new CSV file.
# write sum_age data frame as a CSVwrite.csv(sum_age, file ="sum_age.csv")
Opening a CSV file in Tableau is simple. On the start screen of Tableau Desktop, click on File and then click Open. You can search your computer’s files for a CSV or Excel file to import into Tableau.
Open a new file in Tableau.
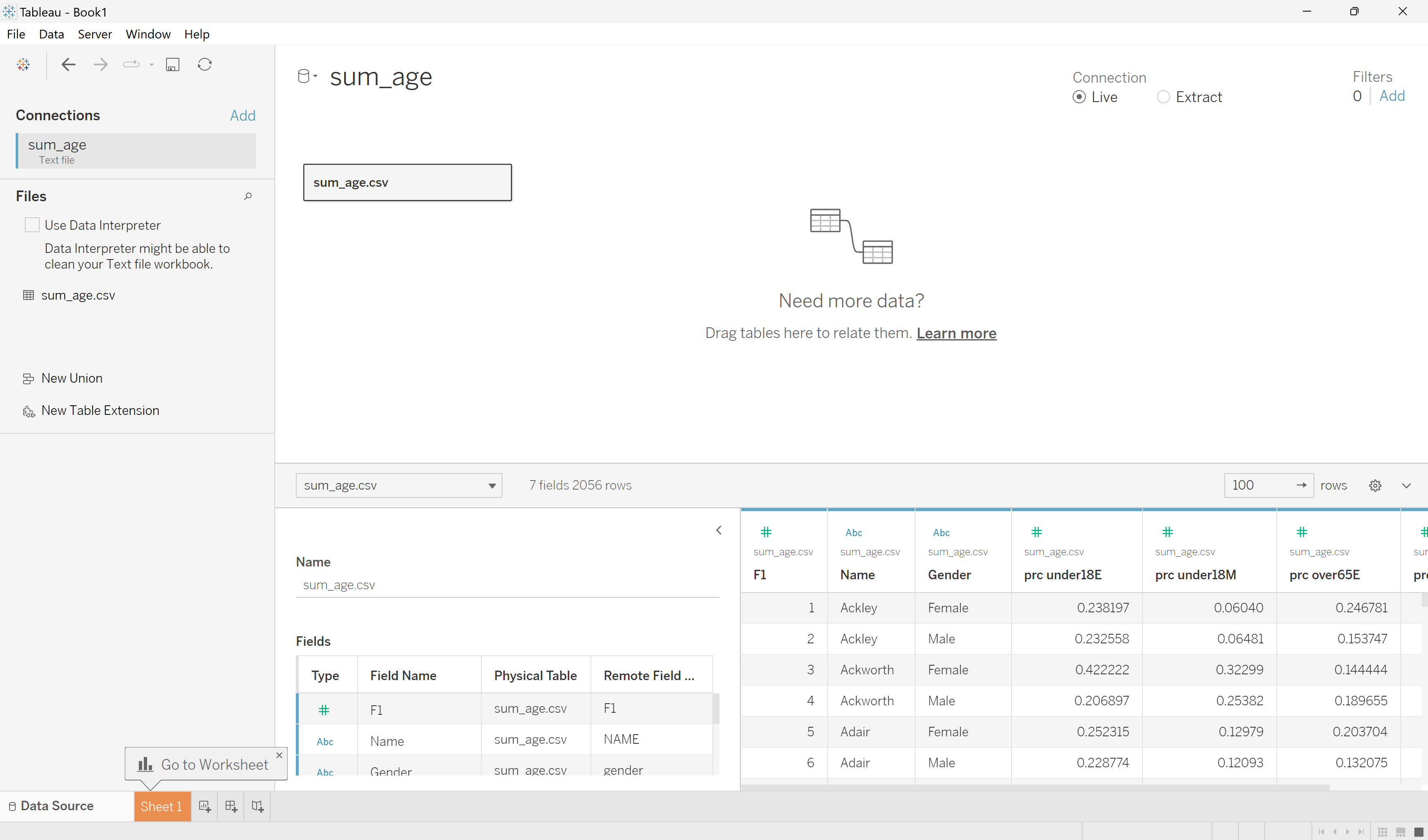
Once the file is opened, your screen should look something like this. The sum_age.csv file is now open in Tableau Desktop, and I can view my data.
Opened data source screen in Tableau.
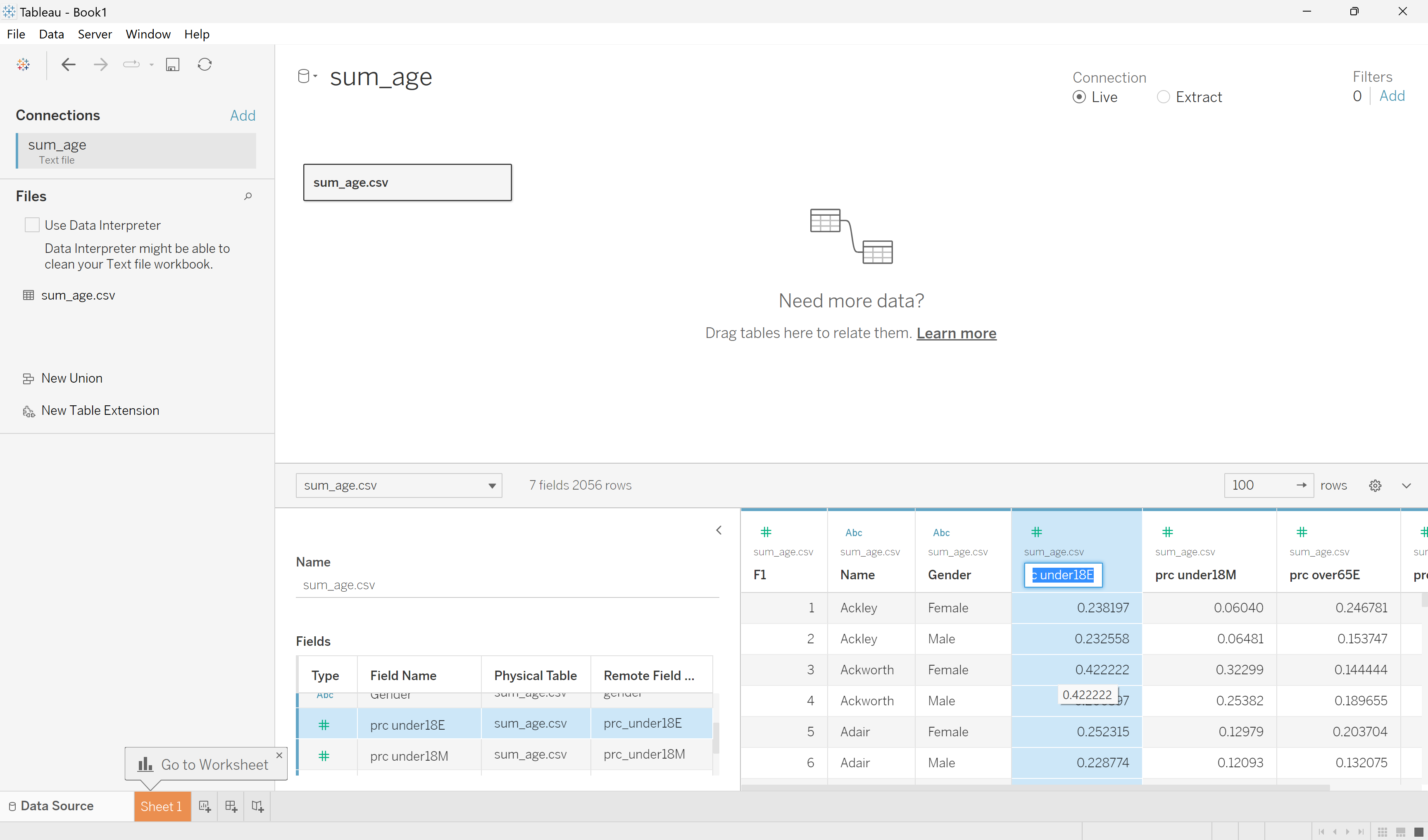
We could have given our columns better names when creating the sum_age.csv file. Fortunately, we can go through and rename the variables in Tableau. Double-click a column name to highlight it, then enter the new name. In the example below, I renamed prc_under18E to “Percent Under 18” and prc_over65E to “Percent Over 65”. You can also hide unnecessary columns by right-clicking on them and selecting Hide. For this visualization, I hid prc_under18M and prc_over65M.
Rename and hide variables.
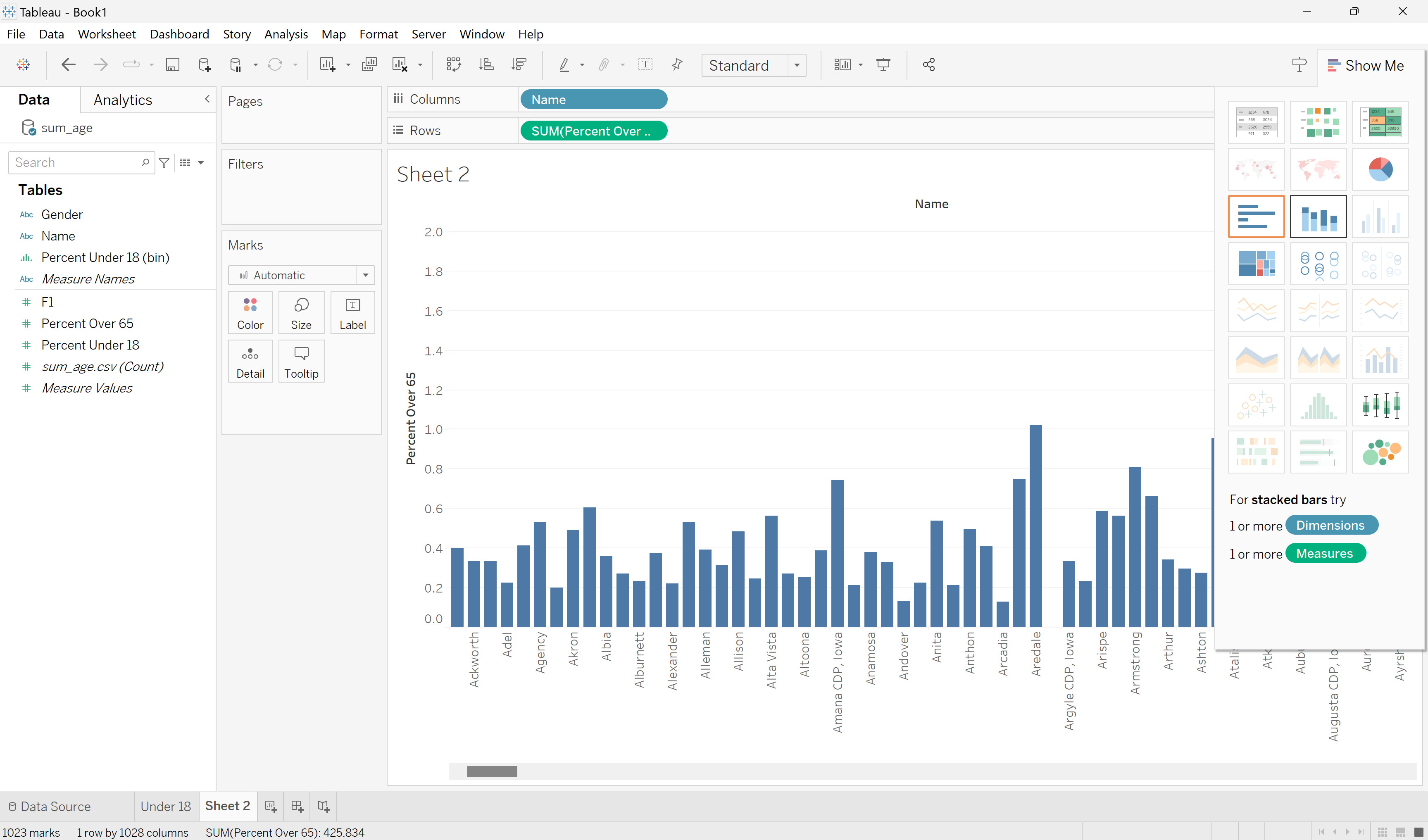
Now that our data is more organized, we can start creating visualizations. Visualizations are made in Sheets in Tableau. To create a visualization, click on Sheet 1. Click and drag Percent Over 65 to Tableau’s Rows section and Name to the Columns section. A bar chart will automatically be made. Tableau will aggregate Percent Over 65 as a sum by default. There are other options for aggregation in Tableau - median, average, min, max, etc. - but sum works just fine for this visualization.
Create a bar chart.
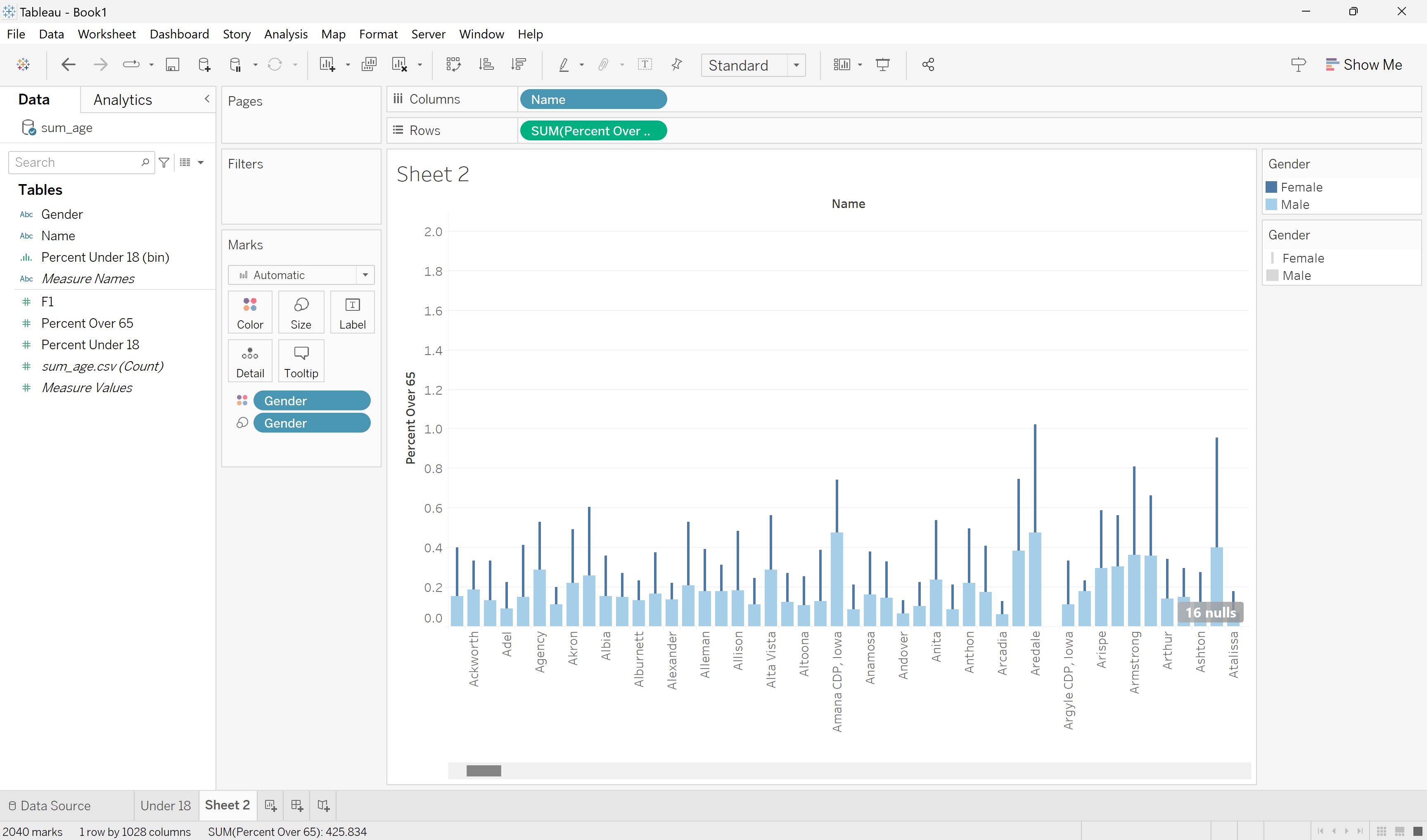
This bar chart is fine but only tells a little about the data. To add more information, let’s add the Gender to represent the color and shape of the bars.
Add gender to the bar chart and represent it by size and color.
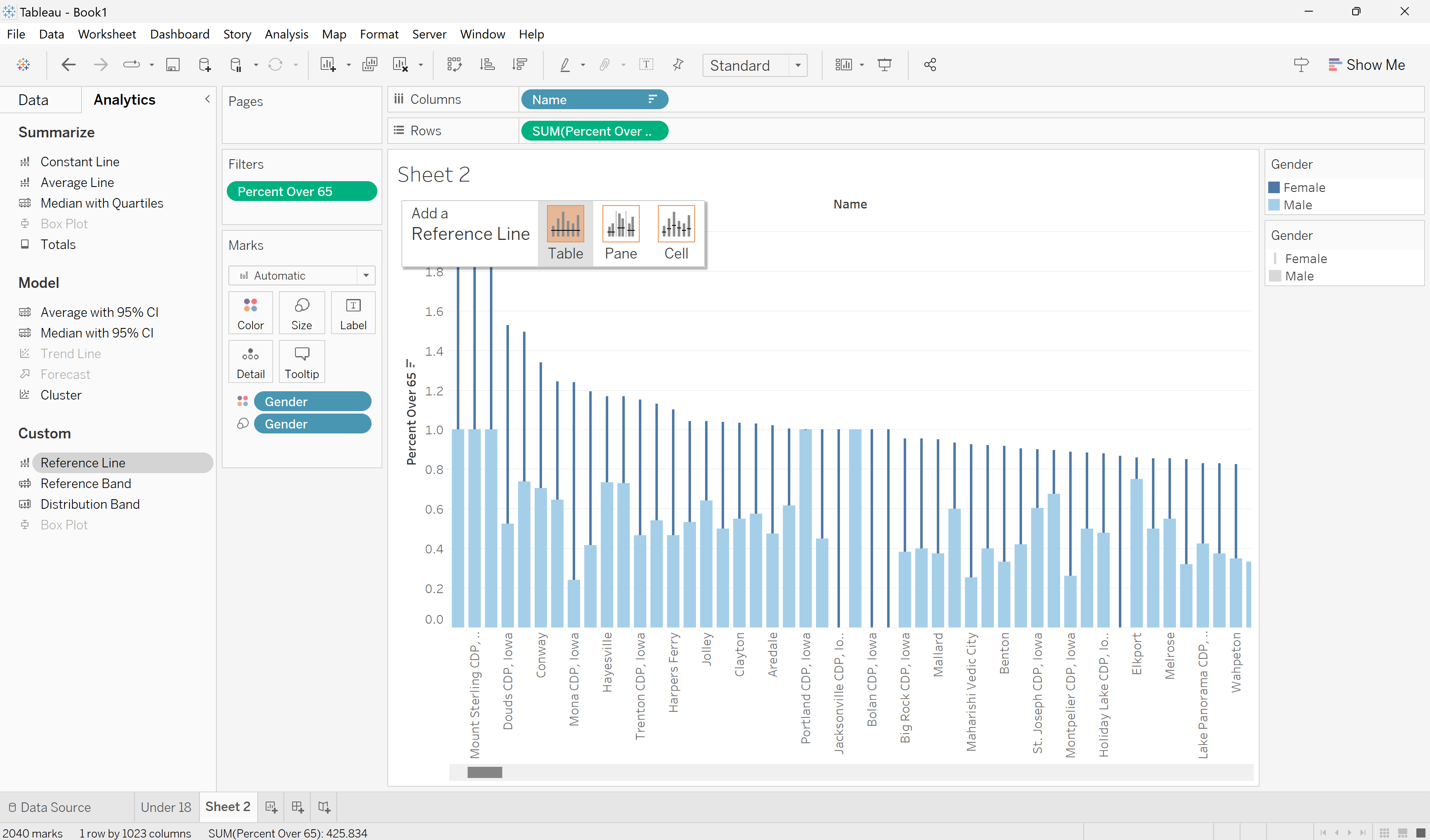
Much better! Now we can see how much of the percentage is for the Female and Male populations. Let’s also add a reference line for the median percent of the total population over sixty-five for all places in Iowa. To add a reference line:
Go to the Analytics tab.
Click and drag Reference Line to the bar chart pane. You will get a pop-up that asks how you want the reference line calculated.
Choose Table.
Add a reference line for median percent over sixty-five.
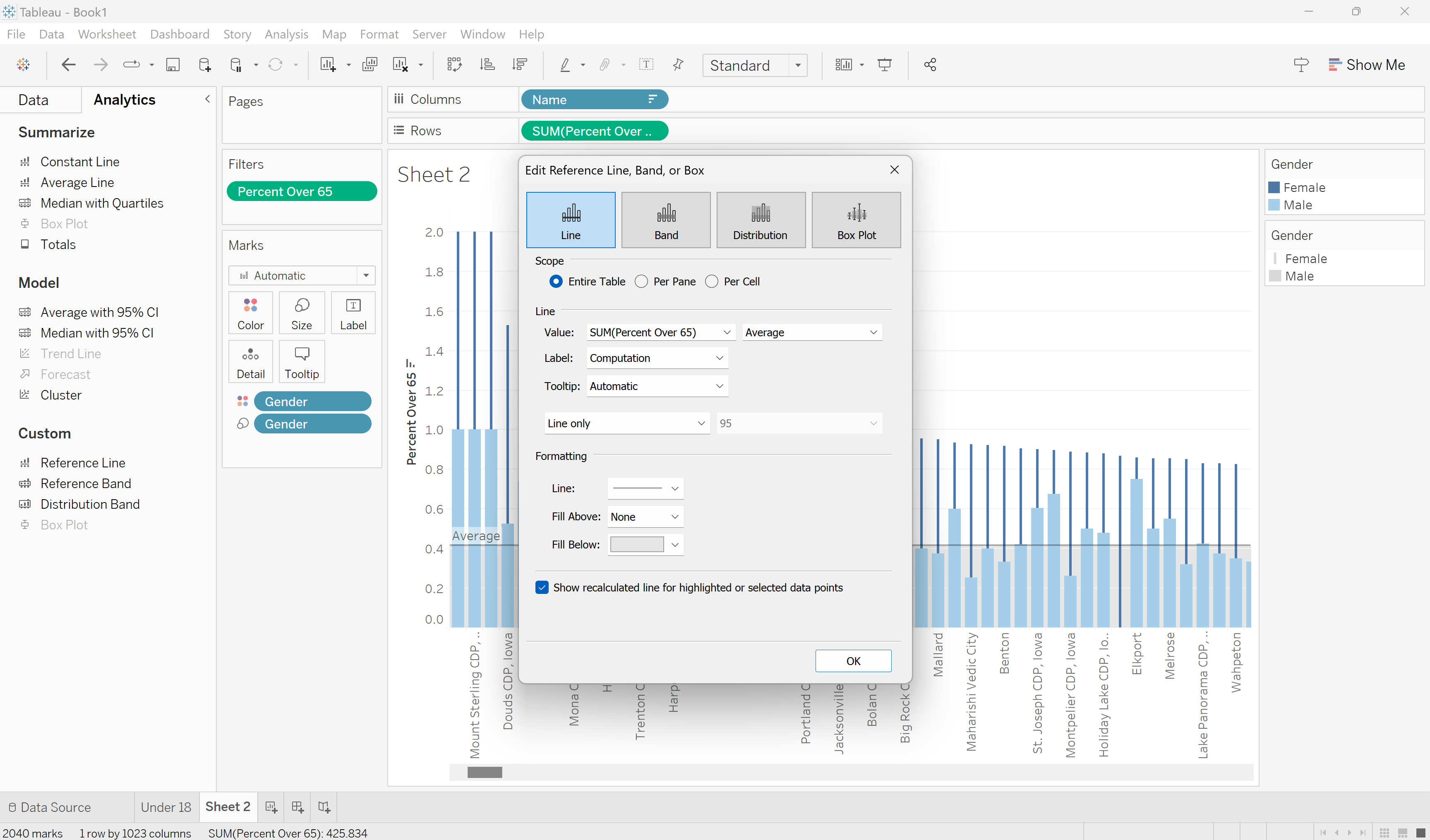
A reference line pane will pop up. Leave all values the same, but change the Fill Below section to a light gray. Coloring in the bottom portion of the chart will highlight the places in Iowa that fall below the average percentage of the population over sixty-five.
Shade the lower section of the reference line.
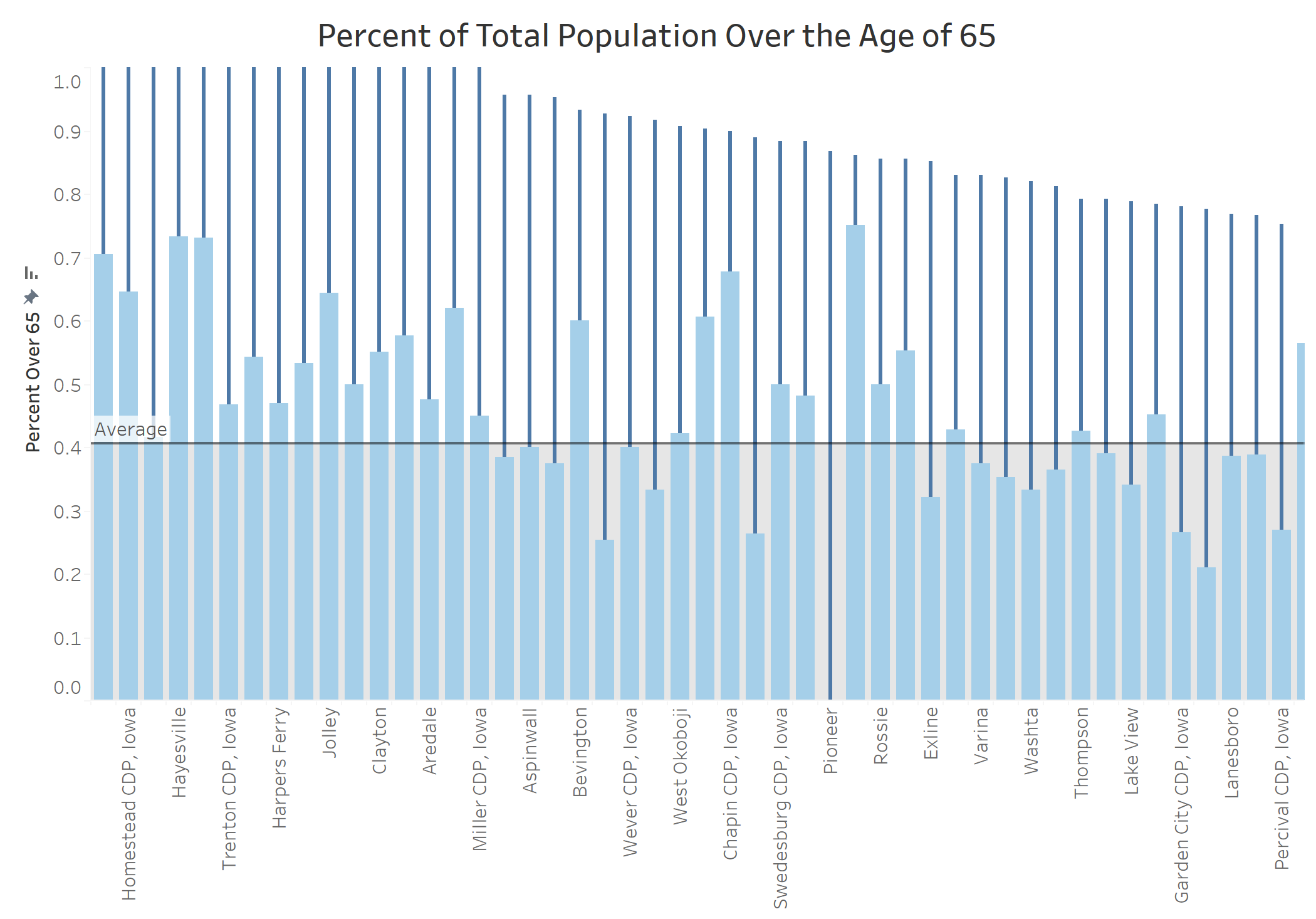
Well done! You have created your first visualization in Tableau.
You can create dashboards and stories in Tableau like this one with a little more practice.
[insert story] !!!!!!!!!!!!!!!!!!!!!!!!!
Creating visualizations like the one above aid in the demographic process by allowing you to see the patterns and trends in the data. You can draw conclusions about a specific state, place, or location by visualizing multiple demographics.
Final Analysis
what can we derive from the created visualization?
IMAGES OF YOUR VISUALIZATIONS !!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!